
Piperka recommendation algorithm
Today, I'll describe how Piperka's recommendation algorithm works. It's a novel approach, mostly because I didn't find the right search words when I wanted one a decade ago. It's a form of collaborative filtering, using only users' comic picks as its input, and it only finds similar items but doesn't do personal recommendations. I was familiar with graph theory, having recently finished my master's thesis on it. So I cobbled something together.
This post has math in it. Just as a refresher about matrix indices: (i,j) denotes the element at row i and column j and (1,1) is the element at top left corner.
My basic idea came from convolutions used in image manipulation, for example as with Gaussian blur or edge detection. In them, the neighbours' pixel values are used to compute a value for each pixel in the image. My idea was to generalise this sort of an operation for graphs, where nodes represent comics and edges get their weights from users reading both comics.
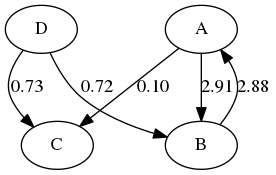
To prepare the data, start with the sum of adjacency matrices over users' comic picks. That is, each (i,j) and (j,i) has the amount of common readers for each comic. I'll be using a small example to demonstrate the steps.

To get a step further from this, we'll calculate a matrix with
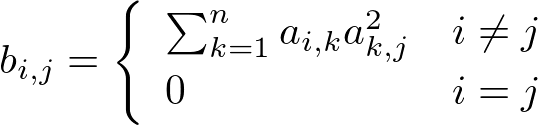
The idea is to assign more weight to edges that lead to other comics that are popular. Matrix A is used to give recommendations and matrix B to reduce their ranking. The idea is that edges in B lead to comics that have in general a lot of readers and may already be known to readers and aren't necessarily of interest in relation to a certain comic. If comics share just a couple of readers they won't get large values in B but if one of them happens to be, say, xkcd, then this would be reflected in B. This is the idea that I got from image manipulation - using the values from neighbors and their neighbors to accentuate close links but to give a minus if a bit further away there would be any bright spots.
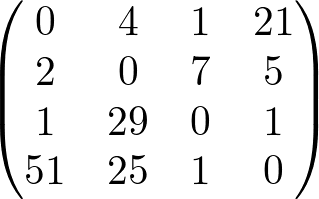
From these, assign some vectors. This is the portion where I started to pretty much randomly throw things together to see what would stick. You can likely tell that I like logarithms.
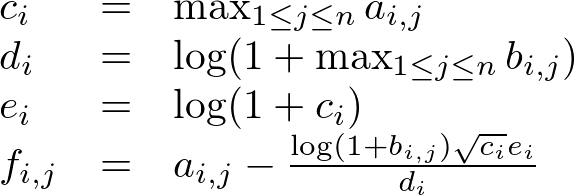
The variables c, d and e are basically in place to try to scale the results to a modest range and F is the matrix for recommendations for each individual comic. Any negative values are automatically dropped from consideration and no results are displayed if all nonnegative values are too close to each other. The example's four nodes are too few to show useful results with the algorithm but it was easier to not let the figures get too busy this way.

I've been meaning to revisit the recommendation algorithm ever since I wrote it, but that will yet have to wait for a long while. I'm sure the formulas in the last step could be tuned better. The recommendation feature has been labeled as "experimental" since I introduced it and it will remain so for the time being. I may yet replace it with some out of the box solution, it's not like Piperka necessarily needs a custom one. I haven't seen an approach quite like mine now that I know more of how these things are usually done. Amazingly enough, it seems to perform reasonably well, at least when applied to comics with a couple of dozen readers at most. I suppose the data I have is pretty challenging, since squeezing out information would always be easier if I had more users and web comics tend to gather a number of very popular entries that most people will end up reading and which are hard to keep from popping up in the results.
I wasn't going to touch it anymore but I did a minor update to the old backend code a while ago since a user asked to have NSFW comics marked in the updates list. I'm making progress with the site backend rewrite but I know better than to promise any dates. I plan to give a status update about it in another post soon.